寻找目标
由于刚刚接触目标,我们肯定要找一个好爬的资讯网站啊,这样爬成功了我们才会有点成就感,以鼓励自己继续学习。此篇文章中,我们以金融之家这个资讯网站为例来爬取文章
爬取之前的工作
分析网站内容,进行抓取
我们借助于chrome浏览器审查元素的功能,首先对网站进行分析

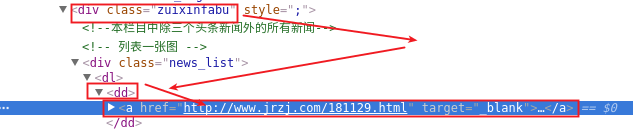
借助于审查元素,我们就可以获取这个元素对应的html标签代码,我们要获取这个元素中的内容,就要通过爬虫找到这个元素的标签,然后处理这个标签从而获得这个元素的内容。
以这样的思路,我们对将要爬取的链接进行分析,由于首页上内容比较乱,我们首先按照某一个分类进行爬取,比如(http://www.jrzj.com/global/)这代表的是分类为”全球”的文章所对应的链接。
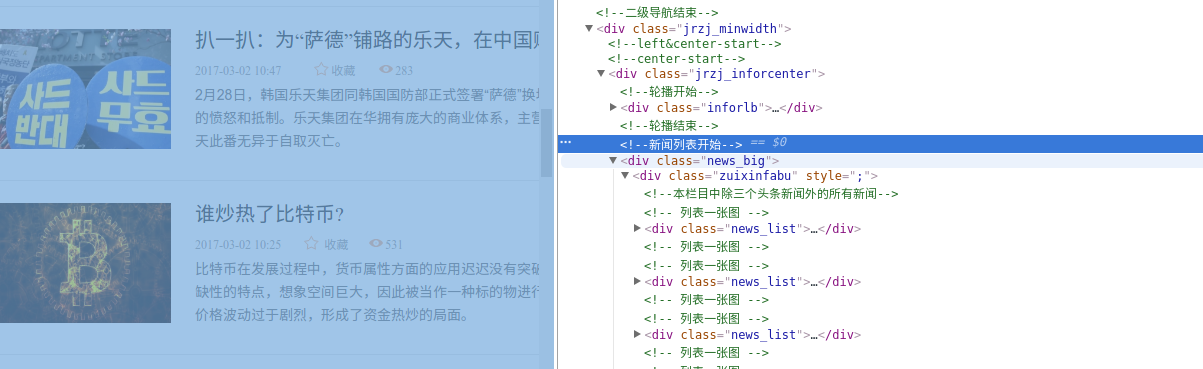
通过审查元素我们可以发现分类中的文章都是一个list,我们需要解析这些标签来获取文章的链接
res=requests.get(url)
res.raise_for_status()
soup=bs4.BeautifulSoup(res.text,'html.parser')
#找到div --'zuixinfabu'--->找到所有dd标签
dd_list=soup.find('div',{'class':'zuixinfabu'}).findAll('dd')
#遍历所有dd标签,取得每篇文章的链接
for dd in dd_list:
articleUrl=dd.find('a',{'target':'_blank'}).get('href')
print('正在爬取:----->%s'%articleUrl)
上面是抓取的一页上的列表中文章链接,那么我们如何抓取其他页面上的呢,很好办,只要我们根据文章列表下的”下一页”对下一页文章列表进行获取就行了

prevLinks=soup.find('div',{'class':'fy_big'}).findAll('a',{'class':'a1'})
for prevLink in prevLinks:
if prevLink.get_text()=='下一页':
url='http://www.jrzj.com/global/'+prevLink.get('href')
这样我们就获得了下一页的链接。根据遍历到最后一页进行结束就可以了
url=('http://www.jrzj.com/global/')
while url!='http://www.jrzj.com/global/list-9-1483-0.html':
print('当前爬取的页面:-------->%s'%url)
res=requests.get(url)
res.raise_for_status()
soup=bs4.BeautifulSoup(res.text,'html.parser')
#找到div --'zuixinfabu'--->找到所有dd标签
dd_list=soup.find('div',{'class':'zuixinfabu'}).findAll('dd')
#遍历所有dd标签,取得每篇文章的链接
for dd in dd_list:
articleUrl=dd.find('a',{'target':'_blank'}).get('href')
print('正在爬取:----->%s'%articleUrl)
prevLinks=soup.find('div',{'class':'fy_big'}).findAll('a',{'class':'a1'})
for prevLink in prevLinks:
if prevLink.get_text()=='下一页':
url='http://www.jrzj.com/global/'+prevLink.get('href')
print('Done')
获取文章内容
要获取文章内容,我们就需要单独分析一篇文章了。我们就获取一个最简单的,文章标题

我们获取文章标题,并且将标题和链接写入文件。
def get_article_title(url):
articleres=requests.get(url)
articleres.raise_for_status()
articlesoup=bs4.BeautifulSoup(articleres.text,'html.parser')
title=articlesoup.h1.get_text()
with open('articeltitle.txt','a') as f:
f.write(url+'-----'+title+'\n')
程序综合
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
import requests,os,bs4
def get_article_title(url):
articleres=requests.get(url)
articleres.raise_for_status()
articlesoup=bs4.BeautifulSoup(articleres.text,'html.parser')
title=articlesoup.h1.get_text()
with open('articeltitle.txt','a') as f:
f.write(url+'-----'+title+'\n')
url=('http://www.jrzj.com/global/')
while url!='http://www.jrzj.com/global/list-9-1483-0.html':
print('当前爬取的页面:-------->%s'%url)
res=requests.get(url)
res.raise_for_status()
soup=bs4.BeautifulSoup(res.text,'html.parser')
#找到div --'zuixinfabu'--->找到所有dd标签
dd_list=soup.find('div',{'class':'zuixinfabu'}).findAll('dd')
#遍历所有dd标签,取得每篇文章的链接
for dd in dd_list:
articleUrl=dd.find('a',{'target':'_blank'}).get('href')
print('正在爬取:----->%s'%articleUrl)
get_article_title(articleUrl)
prevLinks=soup.find('div',{'class':'fy_big'}).findAll('a',{'class':'a1'})
for prevLink in prevLinks:
if prevLink.get_text()=='下一页':
url='http://www.jrzj.com/global/'+prevLink.get('href')
print('Done')
上述就是我们的爬取文章的爬虫。只爬取了文章标题,爬取分析文章内容就留给读者自行考虑。