React 做的一个二维码生成器。
在你的 CMD 或是终端里输入下面这四条命令,如果 git clone 不方便的话,可以直接在 Github 页面下载 ZIP 压缩包。
如果 npm install 报错,尝试入 sudo npm install 并输入电脑密码。
git clone https://github.com/ciaochaos/qrbt……继续阅读 »
破玉
5年前 (2020-06-14) 1887浏览 0评论
0个赞
工具简介
工具地址:github
在线地址:excalidraw
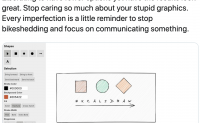
简单介绍:Excalidraw是一种白板工具,可让您轻松地绘制带有手绘感觉的图表。
效果如下
工具使用
在线的话就是官网 excalidraw
离线的话你也可以自行下载后运行
git clone https://github.com/excalidraw/excalidraw.git
……继续阅读 »
破玉
5年前 (2020-06-13) 6803浏览 1评论
2个赞
节点规划
准备部署一主两从 的 三节点 Kubernetes集群,整体节点规划如下表所示:
主机名
IP
角色
k8s-master
192.168.10.246
主节点
k8s-node-1
192.168.10.254
从节点1
k8s-node-2
192.168.10.170
从节点2
所有节点都需要安装以下组件:
Do……继续阅读 »
破玉
5年前 (2020-06-10) 1571浏览 0评论
4个赞
此篇文章是个人以及公司微服务平台落地的一些总结吧。
微服务是什么?
参考链接: https://martinfowler.com/articles/microservices.html
这一点不需要过分罗嗦,简单来说就是将当前单体架构或者SOA架构拆分为一个个的服……继续阅读 »
破玉
5年前 (2020-06-07) 1417浏览 0评论
0个赞
java 堆溢出
我们将Java堆的大小为20M B,不可扩展(将堆的最小值-Xms参数与最大值-Xmx参数设置为一样即可避免堆自动扩展),并设置参数-XX:+HeapDumpOnOutOfMemoryError 转储快照文件
-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
在idea 中可以如……继续阅读 »
破玉
5年前 (2020-05-23) 1687浏览 0评论
3个赞
我们使用的基础镜像是openjdk:8-jdk-alpine。容器启动时第一个进程就是java:
PID USER TIME COMMAND
1 root 0:50 java -Xms256m -Xmx512m ......
94 root 0:00 sh……继续阅读 »
破玉
5年前 (2020-05-07) 6707浏览 1评论
6个赞
MinIO 是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。
……继续阅读 »
破玉
5年前 (2020-05-07) 1434浏览 0评论
0个赞
简介
OpenResty 是一个强大的 Web 应用服务器,Web 开发人员可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,更主要的是在性能方面,OpenResty可以 快速构造出足以胜任 10K 以上并发连接响应的超高性能 Web 应用系统。
360,UPYUN,阿里云,新浪,腾讯网,去哪儿网,酷狗音乐等都是 OpenRes……继续阅读 »
破玉
5年前 (2020-04-23) 3752浏览 0评论
3个赞
参考链接《千万级mysql分页查询优化》
耗时本质
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下。
当一个表数据有几百万的数据的时候成了问题!
如 select * from table limit 0,10 这个没有问题 当 limit 200000,10 的时候数据读取就很慢
原因本质: 1)limit语句的查询时间与起始记录(o……继续阅读 »
破玉
5年前 (2020-04-13) 2218浏览 0评论
1个赞
* Starting control plane node m01 in cluster minikube
* Downloading Kubernetes v1.18.0 preload …
* Updating the running virtualbox “minikube” VM …
! This VM……继续阅读 »
破玉
5年前 (2020-04-08) 6722浏览 0评论
16个赞